
This post is about the generative agents and how they have evolved and are evolving. Throughout the history of AI, people have been fascinated with the prospect of interacting with AI agents. Traditionally, interactions have been restricted to short time horizons and individual conversations such as with ELIZA or the Turing test. The rise of large language models (LLMs) has made it easier to develop persona-based bots (with ChatGPT or Character.ai, for instance) that have a consistent personality but these bots similarly adhere to the persona one conversation at a time.
At the same time, we have already seen glimpses of LLM-powered world-building in applications such as AI dungeon. While it is possible to interact with non-player characters and events in text adventures, characters only exist in relation to the player. What does it take then to generate a world where agents pursue their own goals and objectives regardless of player input? It turns out, LLMs (+ a game engine) are all you need—at least for the small town sandbox created by Park et al. in Generative Agents: Interactive Simulacra of Human Behavior.

In the paper, Park et al. simulate a population of 25 LLM agents in a The Sims-like sandbox environment. Each agent consists of a one-paragraph natural language description depicting its identity and multiple components, each enabled by a LLM (ChatGPT)
Memory and retrieval. A memory stream records events perceived by the agent (with a natural language description, event timestamp, and most recent access timestamp). A retriever retrieves a set of memory objects using a query description based on three factors:
- recency (based on exponential decay since the memory was last retrieved);
- importance (the LLM assigns an importance score based on the memory’s description);
- and relevance (based on embedding similarity with the query).
It is nice to see the return of explicit memory mechanisms, similar in spirit to the key-value memory of Neural Turing Machines and later work. An advantage of this type of memory is interpretability: The contents of the memory of each agent are human-readable and can be inspected at every point in time.
Reflection. Beyond simply remembering past events, an agent should be able to reflects on its experiences and generate higher-level thoughts. To this end, the LLM is queried using the 100 most recent memory records and asked to suggest 3 high-level questions to ask about the subjects in the memory records. For each question, memory records are then retrieved and the model is asked to generate high-level insights based on the retrieved records. The generated insights are then added to the memory, enabling the agent to recursively generate higher-level observations about prior reflections.
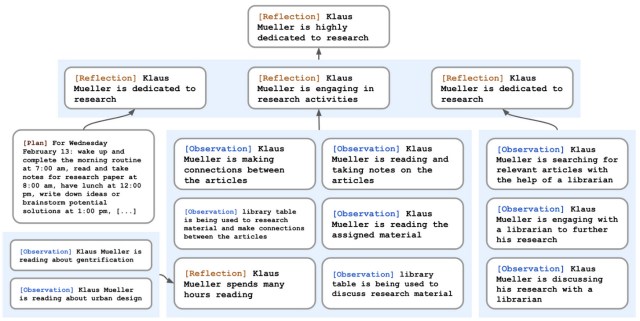
Planning and reacting. To plan what an agent does each day, the authors generate a plan for each day recursively by first generating a rough sketch based on the agent’s description and a summary of their previous day. The LLM decomposes the plan then first into hour-long and again into 5–15 minute chunks.
2 During the day, the LLM is prompted with the perceived observations to decide if and how it should react to a situation. If a reaction is to engage in dialogue with another agent, then the LLMs generate the utterances conditioned on their memories about each other and the previous dialogue history.
LLMs are truly ubiquitous in this work: They are used for retrieval, to assign importance to memories, to suggest what to reflect on, to generate insights, to convert actions to emojis, to generate plans and dialogue, etc. Even the game environment itself is powered by LLMs: In order to determine the appropriate location for each action, the LLM is queried recursively. When an agent executes an action on an object, the LLM is asked about the state of the object. If anything, this demonstrates the versatility of current models.
It is sobering that as a field, we are at a point where many elements of a complex ML agent stack can be replaced with an LLM and an appropriately worded prompt. Most of the above use cases required training a specialized system not long ago, from producing descriptions and explanations of video game actions (Ehsan et al., 2019) to mapping from text to emoji (Eisner et al., 2016). Of course, it will be useful to specialize the model to improve performance for specific use cases such as retrieval or dialogue. While the authors ablate each of the above three components via a human evaluation, I am missing a more fine-grained analysis that highlights for which use cases the LLM is most brittle, which can inform future investigations.
It is unsurprising that the project in its current form costs thousands of dollars to run just with 25 agents. With smaller open-source models, the costs should drop dramatically. The code for the framework in the paper can be found here. Inspired by the paper, researchers from Andreessen Horowitz also made available AI Town, an MIT-licensed starter kit for building and customizing your own virtual town populated by AI characters.

The paper acts as a blueprint of how a framework of AI agents interacting may look like. It is worth pointing out that current models have a range of biases and may exhibit other forms of undesirable behavior that require further study. Nevertheless, there are compelling research directions in the area of multi-agent LLM systems:
- Emergent communication. The emergence of communicative behavior between AI agents has been mainly studied using simple reference games (Chaabouni et al., 2022). What can richer simulated environments tell us about how agents learn to communicate? Can we simulate emergent communication in other settings such as across different languages?
- Nature of communication. Can we use these environments to study aspects of how humans communicate such as speaker accommodation, register change, and code-switching?
- Nature of human behavior and social interaction. Can we study factors involved in other types of higher-level behavior such as planning, organization, co-operation, collaboration, and deception?
- Multi-modal environments. Can we extend environments to incorporate audio and visual inputs and assess how these additional modalities affect the agents’ behavior?
- The expressiveness of simulations. What kind of methods are necessary to simulate even richer interactions? What model scale and capabilities would be necessary to simulate agents and events at the scale of our world?
🏛 Forums for Foundation Models
There was some discussion on Twitter recently about initiating a new conference dedicated specifically to LLMs. LLMs are an interesting technology because they are at the intersection of many different areas of computer science and society including NLP and ML, human-computer interaction, ethics, law, government, education, etc.
So far, work on LLMs has been published in a range of different venues. Much of the foundational work on LLMs (for example, ELMo, ULMFiT, BERT) has been published in NLP (*ACL) conferences, which remain the most topically relevant venue.
The NLP community has studied topics, which are of increasing importance for LLMs, such as automatic evaluation of generative models (Gehrmann et al., 2022) for decades. Recently, researchers have taken issue with the anonymity period but there are initiatives to rethink it.
LLMs have also increasingly become more popular at ML venues. GPT-3 won an outstanding paper award at NeurIPS 2020 while NeurIPS 2022 featured outstanding papers on scaling laws and large-scale image–text datasets. There are also a range of dedicated smaller venues such as the Neural Scaling Laws workshop series. There is even a new conference on Generative Pre-trained Transformer Models and Beyond.
The above venues mainly cater to a computer science audience. As LLMs are increasingly used in user-facing applications, work on LLMs is also published in venues associated with other areas such as the ACM Symposium on User Interface Software and Technology for the paper in the previous section. Given the societal impact of LLMs, it is thus important for any venue to enable an inter-disciplinary dialogue that ensures LLMs are developed in a safe, responsible, and user-appropriate manner.
Besides where to publish, the other issue is who can publish. At the moment, much of the work on LLMs is conducted by labs with large compute budgets. For the previous generation of pre-trained models, an entire array of papers from a diverse range of institutions focused on gaining a better understanding of them.
Such work is needed for the latest generation of large models but is currently prohibitive for many labs. With the release of new powerful open-source models such as Llama-2 combined with better methods for compute-efficient inference, we are heading in a promising direction, however.
- The broader family of LLMs that can learn to act and use auxiliary modules is known as augmented language models. We will discuss these more in-depth in the next edition.
- We have also recently seen plans in other areas such as summarization where question-answer pairs have been used as intermediate representation for conditional generation (Narayan et al., 2022), for instance.
- ACL 2023 had a track dedicated to LLMs.
- Submitted papers are not allowed to be posted, updated, or discussed online from 1 month before the submission deadline until the time of notification (around 4 months in total).
- However, a focus on a specific architecture (and a name associated with a specific model family) may be potentially restrictive in the future.
- This area of study has been commonly referred to as BERTology.